DIY posterior inference, part 1: what does my computer think a probability distribution is?
A short introductory post on pseudo-random number generators and how to actually sample from a probability distribution.
Computation
Statistics
Author
Yann McLatchie
Published
August 31, 2024
Show code
# import JAX, because my code is too shit to go fast otherwiseimport jaximport jax.numpy as jnpfrom jax import randomfrom jax.scipy import special# and also imprt numpy because sometimes I forget what JAX doesimport numpy as np# and we'll probably show some figures laterimport matplotlib.pyplot as plt
I took an introductory course to computational stochastics in my master’s in which we started from pseudo-random number generators and ended up building an HMC kernel. Doing this just once1 helped me a lot in understanding what was happening inside my little silver magic computing box when I power up Stan in the morning. Today, we’re going to speed-run the first part of that course: let’s build our own normal distribution class from scratch.2
Acronymns I can’t remember
First things first, let’s sample a random number uniformly on \([0,1]\). This is a nice place to start, not only because it’s a neatly contained problem, but also because later we will exploit the fact that this interval also happens to be the range of the cumulative probability density function for any proper probability distribution. More to come on that front later.
Most (pseudo-)random number generators (PRNGs) work on the basis modulo arithmetic. We’re going to stick to two easy types of PRNGs for this blog post.3
We start at a seed (which we’ll denote by \(z_0\)) and generate a sequence of “random”4 numbers according to
\[
z_{i+1}^{\textsf{LCG}} = (az_i + c) \mod m.
\]
We call this a linear congruential generator (LCG) or a GGL5. With specific choice of \(m=2^{31} - 1, a=16,807, c=0\), it is called the MLGC6, and people like it7.
Python is our programming choice today8, and the MLGC GGL PRNG9 is implemented quite easily there. We’re using JAX, both so I can play around in JAX and also because I’ve heard it’s quite fast.
class GGL:def__init__(self, m=2**31-1, a=16_807, c=0, seed=1234):"""Initialise GGL settings, defaulting to MLGC settings."""self.m = mself.a = aself.c = cself.seed = seeddef _ggl(self, x):"""GGL random number generator. Args: x (float): sample from previous RNG iteration Yields: float: RNG sample iterations """whileTrue:# GGL sampling from previous iteration x = (self.a * x +self.c) %self.myield xdef sample(self, N):"""Sample from GGL RNG. Args: N (int): number of samples to return Returns: jax.DeviceArray: `N` samples from GGL RNG Examples: >>> import pafnuty.samplers as samplers >>> # initialise RNG object with default settings >>> rng = samplers.GGL() >>> # sample 100 data points from the RNG >>> rng.sample(N=100) """# initialise RNG lcg =self._ggl(self.seed)# return samples from the MLGC RNGreturn jnp.array([next(lcg) for i inrange(N)])def norm_sample(self, N, lower=0, upper=1):"""Normalised samples from GGL RNG. Args: lower (float): the lower bound of uniform samples upper (float): the upper bound of uniform samples N (int): number of samples to return Returns: jax.DeviceArray: N normalised samples from GGL RNG Examples: >>> import pafnuty.samplers as samplers >>> # initialise RNG object with default settings >>> rng = samplers.GGL() >>> # sample 100 normalised data points from the RNG >>> rng.norm_sample(N=100) """# verify boundsif upper <= lower:raiseValueError("Upper bound must be strictly greater than the lower bound." )# make vanilla samples samples =self.sample(N=N)# return normalised samples norm_samples = samples /self.mreturn norm_samples * (upper - lower) + lower
This code is far from optimal. For instance, I should probably replace the yield algorithm with a jax.lax.scan logic like
def _ggl_step(x, _):"""Take a GGL step.""" x_new = (a * x + c) % mreturn x_new, x_new# use LAX to make this fast_, samples = jax.lax.scan(_ggl_step, seed, jnp.arange(N))
but I find what I’ve written more instructive, and it’s not that bad.10
Let’s just check that this is all working as expected. One of the class’ methods is called norm_sample, which will generate normalised samples from the uniform distribution.11 Let’s simulate some samples and plot them.
Show code
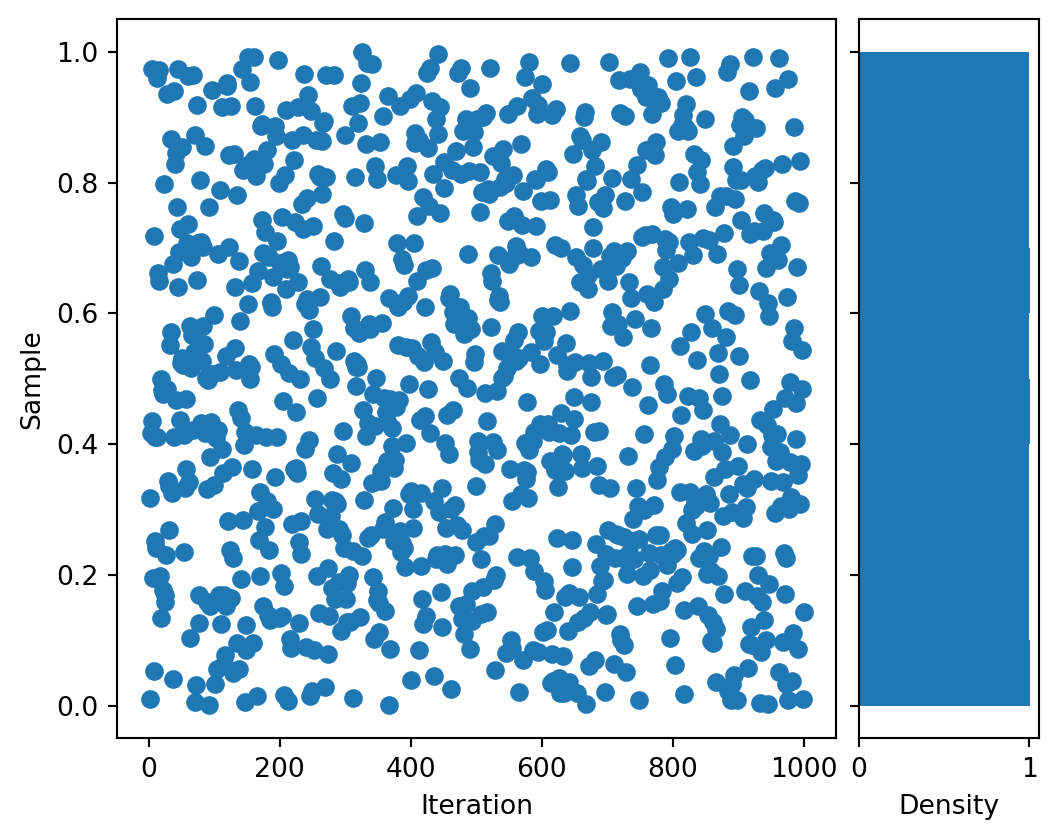
# Draw some samples from a GGLggl = GGL()N =10**6# number of samplesN_plot =1_000# number of samples to show in the scatter plotggl_samples = ggl.norm_sample(N=N)sample_iters = np.arange(1, N_plot +1)# Start with a square Figure.fig = plt.figure(figsize=(6, 6))# Add a gridspec with two rows and two columns and a ratio of 1 to 4 between# the size of the marginal Axes and the main Axes in both directions.# Also adjust the subplot parameters for a square plot.gs = fig.add_gridspec(2, 2, width_ratios=(4, 1), height_ratios=(1, 4), left=0.1, right=0.9, bottom=0.1, top=0.9, wspace=0.05, hspace=0.05)# Create the Axesax = fig.add_subplot(gs[1, 0])ax_hist = fig.add_subplot(gs[1, 1], sharey=ax)# Draw the scatter plotax.scatter(sample_iters, ggl_samples[:N_plot])ax.set_xlabel('Iteration')ax.set_ylabel('Sample')# Add the histogramax_hist.tick_params(axis="y", labelleft=False)ax_hist.hist(ggl_samples, orientation="horizontal", density=True)ax_hist.set_xlabel('Density')# Show the plotplt.show()
Some samples from my home-made GGL machine, along with their density.
Yeah OK that looks fine.12 But let’s just look at one more PRNG while we’re here and I have the code for it.
The RAN313 generator is a specific flavour of lagged Fibonacci generator (LFG). This family of generators is based on the Fibonacci sequence [ z_i^{} = z_{i - 1} + z_{i - 2}. ] And because this on its own doesn’t really do much for us, an LFG will play with the different lags chosen and then throw some modulo addition on top for good measure: \[\begin{equation*}
z_i^{\textsf{LFG}} = z_{i - b} + z_{i - a}\mod m.
\end{equation*}\] Coming back to the RAN3 LFG, all we do now is set \(b = 55, a = 24, m = 10^9\) and replace the modulo addition with modulo subtraction:
This set-up means that we don’t start with just one seed \(z_0\), but actually all the samples \(z_{0:55}\) are needed as a seed. And how should we get these seeds? The GGL class from before!14 Let’s build another Python class, then.
class LFG:def__init__(self, seeds=None, m=10**9, a=24, b=55):""" "Initialise LFG RNG class with RAN3 settings."""self.m = mself.a = aself.b = bif seeds:# check that there are sufficiently many elements in initial seedsiflen(seeds) <self.b:raiseValueError(f"Initial seeds must contain at least {self.b} elements." )self.seeds = seedselse:# initialise seeds from GGL RGNself.ggl = GGL()self.seeds =self.ggl.sample(N=self.b)self.seeds_len =len(self.seeds)def _lfg(self, i, val):""" LFG workhorse function. Args: i (int): Sample number, used to mutate the padded array of seeds. val (jax.DeviceArray): Current state of the seeds. Returns: jax.DeviceArray: Updated state of the seeds with the new sample. """# compute the next value using the LFG idx =self.seeds_len + i next_val = (val[idx -self.b] - val[idx -self.a]) %self.m val = val.at[idx].set(next_val)# return updated samplesreturn valdef sample(self, N):"""Samples from LFG RNG with RAN3 settings. Args: N (int): number of samples to return Returns: jax.DeviceArray: N samples from LFG RNG Examples: >>> import pafnuty.samplers as samplers >>> # initialise RNG object with default settings >>> rng = LFG() >>> # sample 100 data points from the RNG >>> rng.sample(N=100) """# Use jax.lax.fori_loop to efficiently generate N samples seeds = jnp.concatenate([self.seeds, jnp.zeros(N)]) samples = jax.lax.fori_loop(0, N, self._lfg, seeds)# Return the N generated samplesreturn samples[-N:]def norm_sample(self, N, lower=0, upper=1):"""Normalised samples from LFG RNG. Args: lower (float): the lower bound of uniform samples upper (float): the upper bound of uniform samples N (int): number of samples to return Returns: jax.DeviceArray: N normalised samples from LFG RNG Examples: >>> import pafnuty.samplers as samplers >>> # initialise RNG object with default settings >>> rng = LFG() >>> # sample 100 normalised data points from the RNG >>> rng.norm_sample(N=100) """# verify boundsif upper <= lower:raiseValueError("Upper bound must be strictly greater than the lower bound." )# make vanilla samples samples =self.sample(N=N)# return normalised samples norm_samples = samples /self.mreturn norm_samples * (upper - lower) + lower
Another quick test to see how it’s looking…
Show code
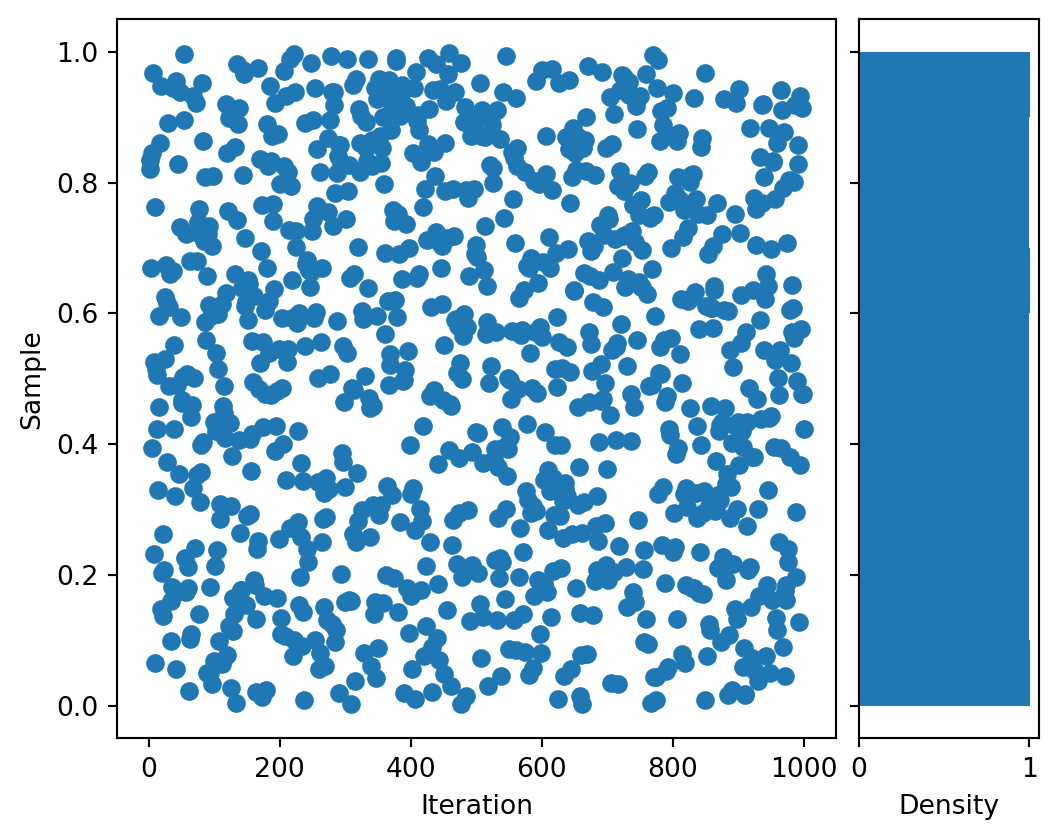
# Draw some samples from a GGLlfg = LFG()lfg_samples = lfg.norm_sample(N=N)# Start with a square Figure.fig = plt.figure(figsize=(6, 6))# Add a gridspec with two rows and two columns and a ratio of 1 to 4 between# the size of the marginal Axes and the main Axes in both directions.# Also adjust the subplot parameters for a square plot.gs = fig.add_gridspec(2, 2, width_ratios=(4, 1), height_ratios=(1, 4), left=0.1, right=0.9, bottom=0.1, top=0.9, wspace=0.05, hspace=0.05)# Create the Axesax = fig.add_subplot(gs[1, 0])ax_hist = fig.add_subplot(gs[1, 1], sharey=ax)# Draw the scatter plotax.scatter(sample_iters, lfg_samples[:N_plot])ax.set_xlabel('Iteration')ax.set_ylabel('Sample')# Add the histogramax_hist.tick_params(axis="y", labelleft=False)ax_hist.hist(lfg_samples, orientation="horizontal", density=True)ax_hist.set_xlabel('Density')# Show the plotplt.show()
And now some samples from my home-made LFG RAN3 machine, along with their density.
And it seems just fine.
But let’s look closer at these two generators. We separate the samples into two sub-arrays of alternating samples
which we then plot against each other. This will help us better understand if there is any dependency between subsequent samples from the two generators.
Show code
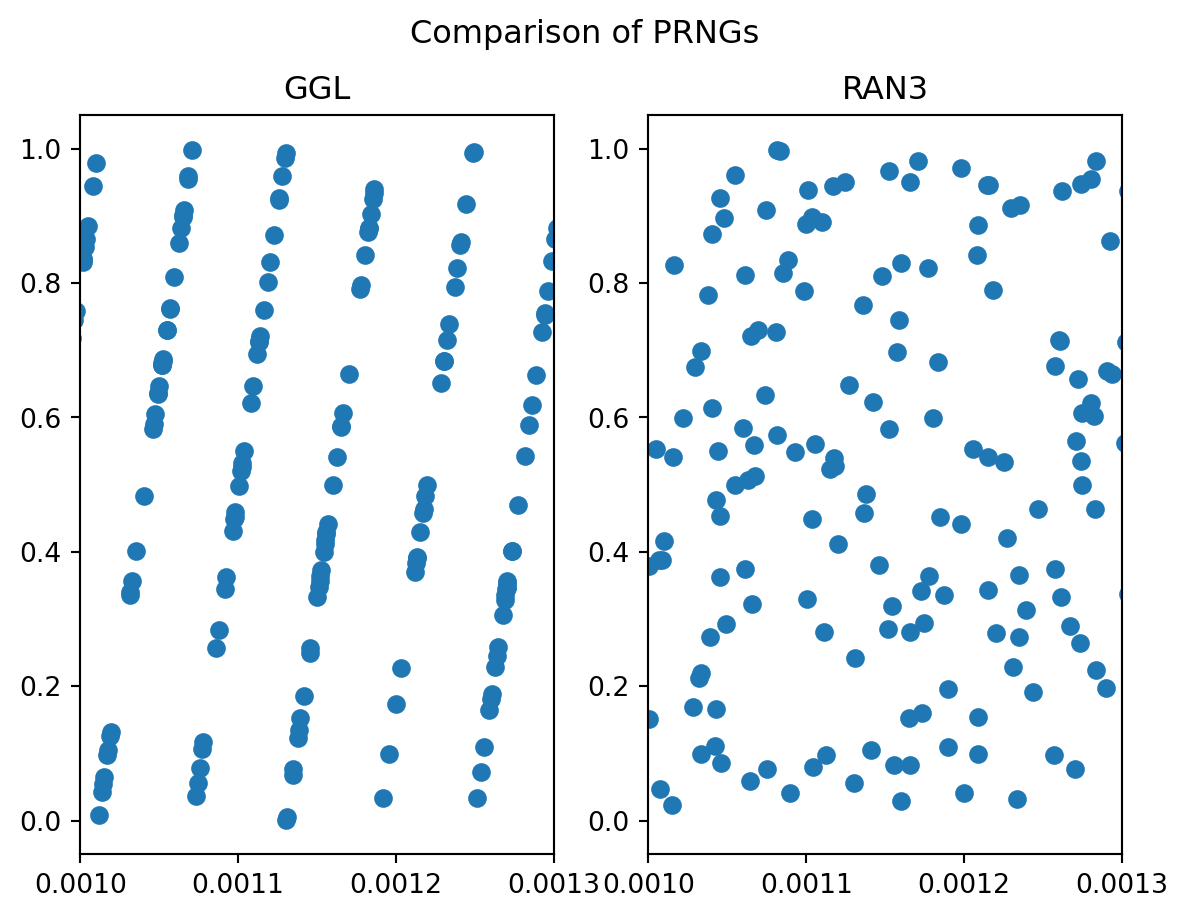
# take X and Y as x,y,x,y,x,y,... from samples X_ggl, Y_ggl = ggl_samples[::2], ggl_samples[1::2]X_lfg, Y_lfg = lfg_samples[::2], lfg_samples[1::2]# plot the two PRNGs togetherfig, (ax1, ax2) = plt.subplots(1, 2)fig.suptitle("Comparison of PRNGs")# plot GGLax1.set_title("GGL")ax1.set_xlim(10**-3, 1.3*10**-3)ax1.plot(X_ggl, Y_ggl, "o")# plot RAN3ax2.set_title("RAN3")ax2.set_xlim(10**-3, 1.3*10**-3) ax2.plot(X_lfg, Y_lfg, "o")
Looking more closely at the generation pattern of PRNGs
We see that the GGL has a clear and repeating pattern due to its modulo addition logic. The same is not true, however, for the RAN3 generator which operates on different lagged samples. Let’s move on to the fun stuff, favouring the LFG for (normalised) uniform sampling.
Transformers: inverse
So here’s what we can do so far: sample uniformly on the interval \([0,1]\). Yay. Let’s get a bit more exciting now and sample from an arbitrary probability distribution \(X\).
Well, we know that if \(X\) is a continuous random variable with cumulative distribution function \(F_X\), then the random variable defined by \(Y = F_X(X)\) has a uniform distribution on the range \([0,1]\). So, if \(Y\) has a uniform distribution, then we also know that \(F^{−1}_X(Y)\) has the same distribution as \(X\). We’re getting somewhere!
Consider a Gaussian15 random variable \(X\) with mean \(\mu\) and variance \(\sigma^2\), then its cumulative distribution function (CDF) is
So now, we should be able to take \(n\) samples (which we’ll call \(y_{1:n}\)) from our GGL from before, pass them through \(F^{-1}_X\) and get in return \(x_{1:n} = F^{-1}_X(y_{1:n}) \overset{\text{iid}}{\sim}\mathcal{N}(\mu,\sigma^2)\)!
B.Y.O.Distribution class
We’re going to reimplement the wheel, because it’s a bit instructive. A probability distribution class should have16:
a probability density function;
a log probability density function;
a cumulative density function;
and inverse cumulative density function;
the derivative of the “potential” (which means the log pdf)17; and.
a method to natively sample from that distribution.
So, because I haven’t done any real Python dev in a while, let’s make a distribution class to inherit from.18
class Dist:"""Base probability distribution class."""def pdf(x):raiseNotImplementedErrordef logpdf(x):raiseNotImplementedErrordef cdf(x):raiseNotImplementedErrordef invcdf(x):raiseNotImplementedErrordef dVdQ(x):raiseNotImplementedErrordef sample(N):raiseNotImplementedError
Isn’t Python dev fun! Right, let’s fill in the blanks here for a Gaussian distribution.
class Normal(Dist):"""Normal distribution class."""def__init__(self, mu=0, sigma=1, seed=12345):"""Initialise the distribution's parameters."""self.mu = muself.sigma = sigmaself.name ="Normal"self.key = random.PRNGKey(seed)self.rng = LFG()def pdf(self, x):"""Return the probability distribution at a point x. Args: x (float, int): the point at which to compute the PDF. Returns: jax.DeviceArray: a one element sized DeviceArray containing the value of the PDF at x. """return (jnp.exp(-1* ((x -self.mu) **2) / (2*self.sigma**2))) / (self.sigma * jnp.sqrt(2* jnp.pi) )def logpdf(self, x):"""Return the log probability distribution at a point x. Args: x (float, int): the point at which to compute the log of the PDF. Returns: jax.DeviceArray: a one element sized DeviceArray containing the log of the value of the PDF at x. """return jnp.log(self.pdf(x))def cdf(self, x):"""Return the cumulative probability distribution up to point x. Args: x (float, int): the point up to which to compute the CDF. Returns: jax.DeviceArray: a one element sized DeviceArray containing the value of the CDF up to x. """return1/2* (1+ special.erf((x -self.mu) / (self.sigma * jnp.sqrt(2))))def invcdf(self, x):"""Return the inverse cumulative probability distribution up to point x. Args: x (float, int): the point up to which to compute the inverse CDF. Returns: jax.DeviceArray: a one element sized DeviceArray containing the value of the inverse CDF up to x. """returnself.mu +self.sigma * special.erfinv(2* x -1) * jnp.sqrt(2)def dVdQ(self, x):"""Return gradient of potential at a point x with JAX autodiff. Args: x (float): the point at which to compute the gradient of the potential Returns: jax.DeviceArray: a one element sized DeviceArray containing the gradient of the potential at x. """ifnotisinstance(x, float):raiseValueError("dVdQ accepts only real or complex-valued inputs, not ints." )return jax.grad(self.logpdf)(x)def sample(self, N):"""Sample N data points from the normal distribution. This method leverages the inverse cumulative distribution sampling technique to draw its samples using our native pseudo-RNGs. Args: N (int): the number of samples to draw from the distribution. Returns: jax.DeviceArray: DeviceArray of N samples from distribution. """ u =self.rng.norm_sample(N=N) x =self.invcdf(u)return x
Most of these methods are just translating the Wikipedia article for the univariate Gaussian into JAX, but have look at the sample method. In order to generate N samples from the Gaussian we first generate N samples from the uniform on the unit interval, and then transform them according to the quantile function. How satisfying!
Let’s instantiate a \(\mathcal{N}(0, 1)\) and draw some samples from it to make sure this is all working as intended.
Show code
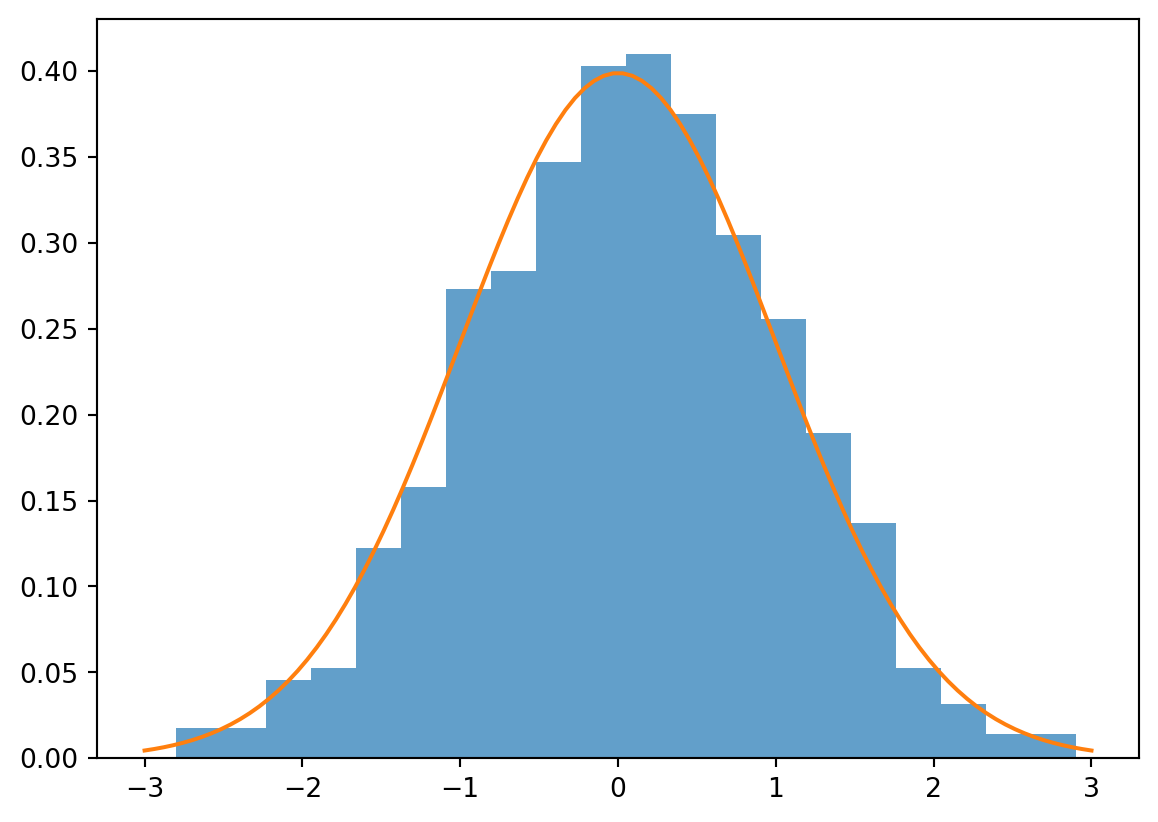
# define the Gaussian and pull some samplesmu =0sigma =1dist = Normal(mu = mu, sigma = sigma)samples = dist.sample(N=1_000)# plot the samples compared to the true densityplt.hist(samples, bins =20, density =True, alpha =0.7)x_linspace = jnp.linspace(mu -3* sigma, mu +3* sigma, 100)plt.plot(x_linspace, jax.scipy.stats.norm.pdf(x_linspace, mu, sigma))plt.show()
Some samples from my bootlegged Gaussian, along with a sanity check from real-life developers.
OK that’s pretty much it for defining your own probablity distribution class. Join us next time on “Yann does some stuff in Python for a change”, where we will have a stab at Hamiltonian Monte Carlo!
Footnotes
And then never again, because to be fair I wanted to enjoy my master’s.↩︎
OK fine not completely from scratch, we’re still going to lean on some numpy internals for arithmetic.↩︎
Most people these days like the Mersenne-Twister, but I want to implement something easy because it’s Saturday and I want to go watch a film later.↩︎
Actually, it looks better than what I was expecting …↩︎
Look, I don’t know what half of these stand for, I’m really sorry. But it shouldn’t matter too much either since most people will just use the native one in their favourite programming language, which probably is the Mersenne-Twister anyway.↩︎
No scraps in this blog post, we’re going to use every method we write eventually.↩︎
This will not improve the performance of the algorithm in any way. It’s just more unnecessary work for this post. But I want to do it. So we’re doing it.↩︎
Citation
BibTeX citation:
@online{mclatchie2024,
author = {Yann McLatchie},
title = {DIY Posterior Inference, Part 1: What Does My Computer Think
a Probability Distribution Is?},
date = {2024-08-31},
url = {https://yannmclatchie.github.io/blog/posts/scratch-hmc-1},
langid = {en}
}